Real-Time Streaming Data Pipeline
A scalable streaming data pipeline built with Kafka and Flink processing real-time events for analytics, ML models, and operational dashboards. Features exactly-once processing guarantees, auto-scaling, and multi-region deployment for global availability.
Project Overview
Technologies Used
Ready for similar results?
Let's discuss how we can help you achieve your goals with our expertise.
Schedule a Consultation →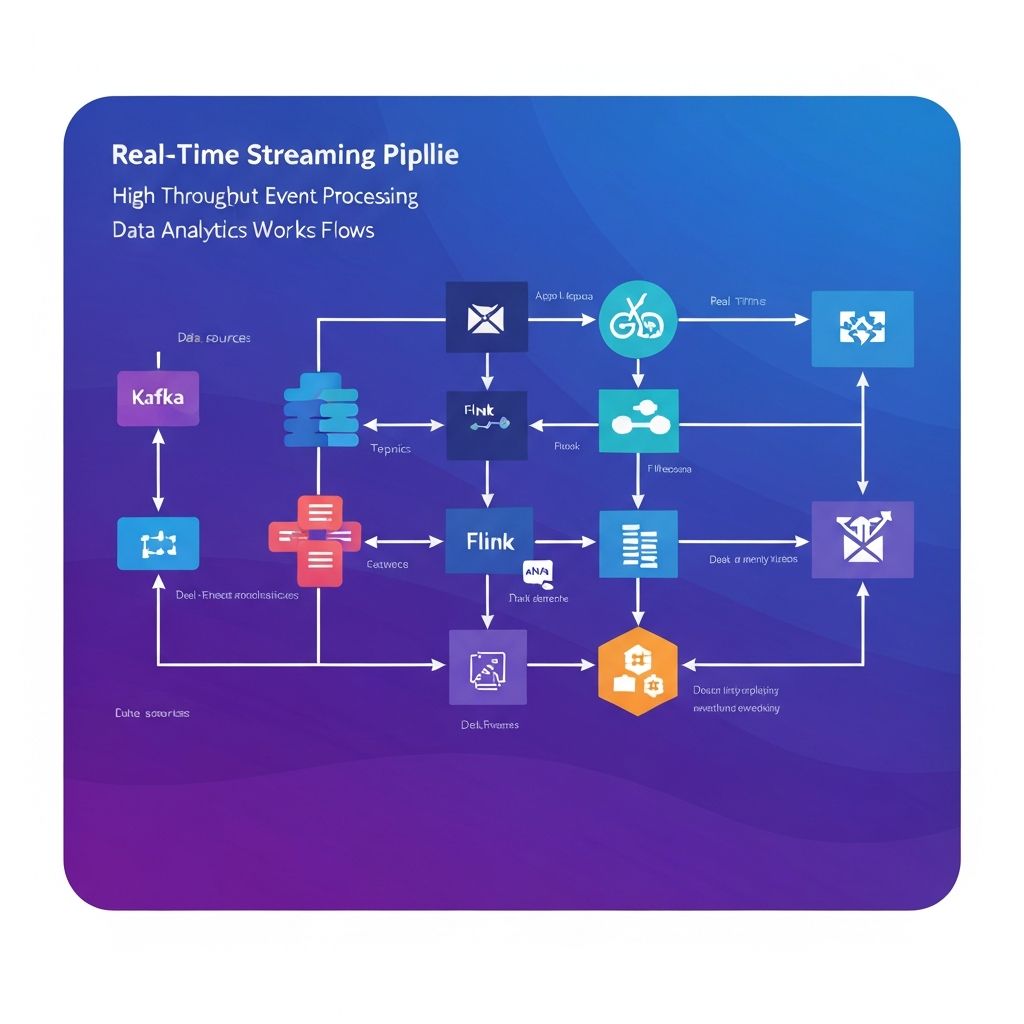
The Challenge
Batch processing caused 6-hour delays in analytics, preventing real-time decision making. System couldn't handle traffic spikes during viral events. Data quality issues from duplicate and missing events created inaccurate analytics.
Our Solution
We architected a real-time streaming pipeline with Apache Kafka for ingestion and Apache Flink for processing. Implemented exactly-once semantics, auto-scaling based on queue depth, and multi-region deployment. Built data quality checks and monitoring dashboards for operational visibility.
Our Approach
Apache Kafka
Core framework powering the application architecture and user experience.
Apache Flink
Essential technology enabling scalability and performance optimization.
AWS MSK
Critical infrastructure component for data management and persistence.
S3
Supporting technology enhancing system capabilities and integration.
Kubernetes
Additional tooling for monitoring, deployment, and operations.
The Results
10M+ events processed per second
150ms p99 end-to-end latency
99.99% availability across regions
From 6-hour batch to real-time insights
Auto-scaling during viral traffic spikes
Exactly-once processing guarantees
Real-time ML model serving with fresh features
Key Metrics
Business Impact
Enabled real-time personalization and content moderation at scale, directly improving user engagement and platform safety. Foundation for ML-powered features.
Ready to Achieve Similar Results?
Let's discuss how we can help you transform your business with cutting-edge technology solutions.